
 | High Availability (HA) and Disaster Recovery (DR) capabilities continue to improve in Skype for Business Server 2015 to provide even greater uptime reliability and performance for end users. Fundamentally the Front-End HA/DR capabilities are built upon the Windows Fabric v1 foundation that was introduced in Lync Server 2013, and now improved with v3 in Skype4B server, For the Back-End servers the redundancy is built on SQL Mirroring or Always-On technologies This article aims to provide some of the best practices for Front End Server HA+DA in Skype4B server. For readers already familiar with these concepts, then this article can also serve as a refresher and/or reference. |
Ensuring Pool Quorum and Routing Group Quorum
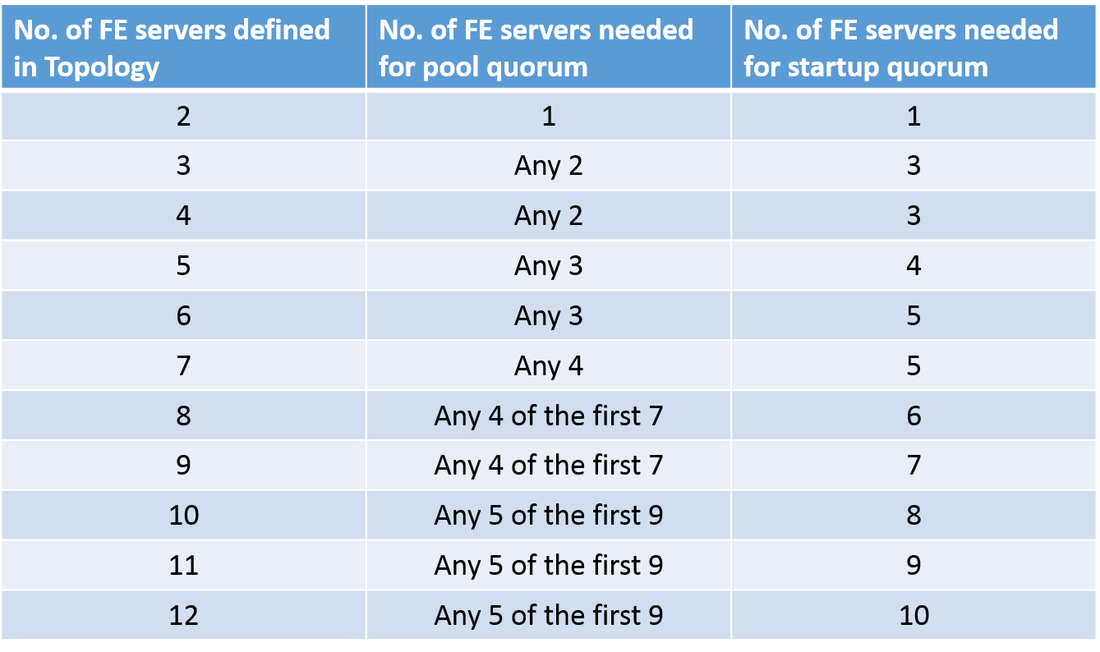
HA in the Skype4B Front-End pool is the ability of the server pool to continue servicing users in the event of a failure of 1 or more servers within the pool. Front-End pool HA is based on clustering via HLB and DNS load balancing built into the servers to automatically distribute groups of users across the various front end servers in a pool. During startup, 85% of all servers in the pool must be started in order for the entire pool to be functional. This is known as achieving Routing Group level Quorum. After the pool is operational, then only 50% of the servers in the pool must be running in order for the pool to remain functional. This is called achieving Pool Level Quorum and is not to be confused with Routing Group Level Quorum. The table below shows the numbers for these two quorum types:
HA in the Skype4B Front-End pool is the ability of the server pool to continue servicing users in the event of a failure of 1 or more servers within the pool. Front-End pool HA is based on clustering via HLB and DNS load balancing built into the servers to automatically distribute groups of users across the various front end servers in a pool. During startup, 85% of all servers in the pool must be started in order for the entire pool to be functional. This is known as achieving Routing Group level Quorum. After the pool is operational, then only 50% of the servers in the pool must be running in order for the pool to remain functional. This is called achieving Pool Level Quorum and is not to be confused with Routing Group Level Quorum. The table below shows the numbers for these two quorum types:
To help achieve quorum, we should never define more servers in the topology than what is actually deployed. If the number of servers fall below the 85% Routing Group Level quorum but there are still enough servers to maintain Pool Level quorum, then the Reset-CsPoolRegistrarState -ResetType QuorumLossRecovery cmdlet can be used to reload user data from the backup store for any routing groups currently in quorum loss.
Deploy at least 3 FE servers
Although a 2-node FE server pool can be deployed, the minimum recommended number of FE servers is 3. This is due to how Windows Fabric distributes users into Routing Groups which are automatically created and increases as more users are added. Each Routing Group has 3 replicas of user data: Primary, Secondary and Backup Secondary. User requests are always serviced by the Primary replica and all users assigned to a Group are always homed on the same FE server. Windows Fabric v3 will perform synchronous writes to all three replicas and only periodic writes to the back-end BLOB database for rehydration purposes with the exception of Conference State data. To view the replica set information for a particular user, we can use the Get-CsUserPoolInfo "domain\username" cmdlet:
Although a 2-node FE server pool can be deployed, the minimum recommended number of FE servers is 3. This is due to how Windows Fabric distributes users into Routing Groups which are automatically created and increases as more users are added. Each Routing Group has 3 replicas of user data: Primary, Secondary and Backup Secondary. User requests are always serviced by the Primary replica and all users assigned to a Group are always homed on the same FE server. Windows Fabric v3 will perform synchronous writes to all three replicas and only periodic writes to the back-end BLOB database for rehydration purposes with the exception of Conference State data. To view the replica set information for a particular user, we can use the Get-CsUserPoolInfo "domain\username" cmdlet:
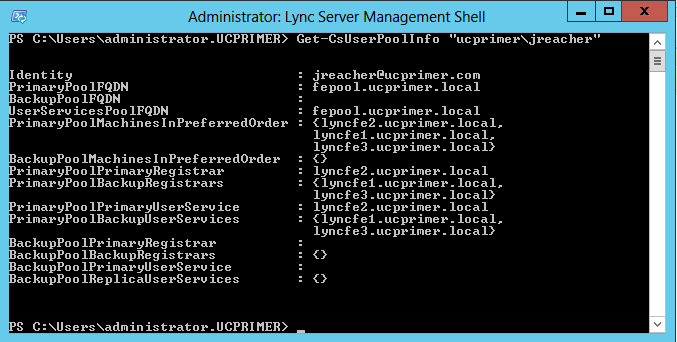
As shown in the screenshot above, the user "jreacher" is assigned a primary replica at lyncfe2 with lyncfe1 and lyncfe3 as secondary replicas. With a 2-node only FE Pool, Windows Fabric will be unable to build the 3-member replica set and therefore will perform synchronous writes to the backend database, affecting overall server performance.
Recovering from Quorum Loss
Lets start by reviewing the user experience when quorum loss occurs. Since all user requests are serviced by the Primary replica, if one of the secondary replicas were to go down, there will be no impact to the user at all. If the Primary replica goes down, then one of the Secondary replicas will be promoted to become the Primary. The user will only experience a brief disconnect before full services are restored. If two of the replicas were to go down at the same time, the user will be placed into "Limited Functionality" mode while all three replicas down means the user will be disconnected and the client will forever be in a "Reconnecting..." state.
To recover from quorum loss, the administrator needs to run the Reset-CsPoolRegistrarState -ResetType QuorumLossRecovery cmdlet to tell Windows Fabric to rebuild the replicas on the remaining FE servers, assuming there are enough to maintain pool quorum. This cmdlet reloads user data from the backup store for any routing groups currently in quorum loss but any data not yet written to the database could be lost when doing this.
It's worthwhile noting that the "FullReset" option for this cmdlet performs the same type of reset as "QuorumLossRecovery" but in addition, rebuilds the local Skype for Business Server 2015 databases. This type of reset can be potentially long and resource-intensive and is typically only used when changing a topology from a pool with a single Front End server to a pool with multiple Front End servers. Using the "FullReset" value when attempting to restart a pool will sometimes result in failure, and the pool will not actually restart. Hence, never do Reset-CsPoolRegistrarState -ResetType FullReset without MS Support Assistance.
Lets start by reviewing the user experience when quorum loss occurs. Since all user requests are serviced by the Primary replica, if one of the secondary replicas were to go down, there will be no impact to the user at all. If the Primary replica goes down, then one of the Secondary replicas will be promoted to become the Primary. The user will only experience a brief disconnect before full services are restored. If two of the replicas were to go down at the same time, the user will be placed into "Limited Functionality" mode while all three replicas down means the user will be disconnected and the client will forever be in a "Reconnecting..." state.
To recover from quorum loss, the administrator needs to run the Reset-CsPoolRegistrarState -ResetType QuorumLossRecovery cmdlet to tell Windows Fabric to rebuild the replicas on the remaining FE servers, assuming there are enough to maintain pool quorum. This cmdlet reloads user data from the backup store for any routing groups currently in quorum loss but any data not yet written to the database could be lost when doing this.
It's worthwhile noting that the "FullReset" option for this cmdlet performs the same type of reset as "QuorumLossRecovery" but in addition, rebuilds the local Skype for Business Server 2015 databases. This type of reset can be potentially long and resource-intensive and is typically only used when changing a topology from a pool with a single Front End server to a pool with multiple Front End servers. Using the "FullReset" value when attempting to restart a pool will sometimes result in failure, and the pool will not actually restart. Hence, never do Reset-CsPoolRegistrarState -ResetType FullReset without MS Support Assistance.
Avoid deploying even number of FE servers when using SQL Mirroring
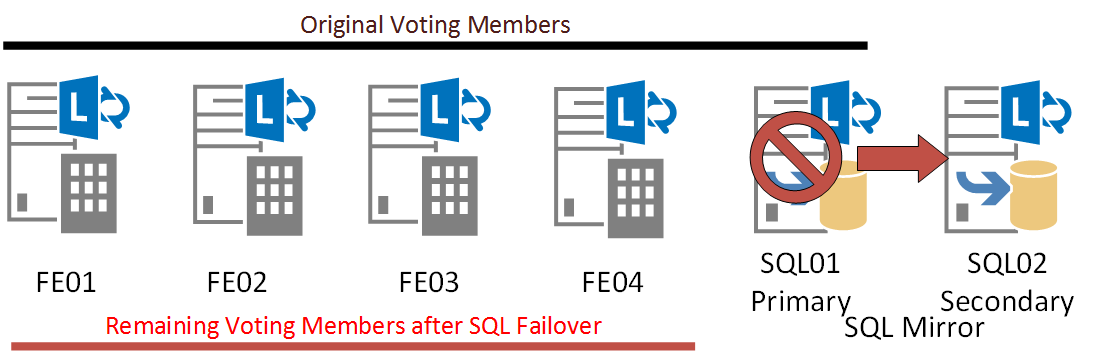
When determining the number of servers running in a pool, Windows Fabric uses a voting process that requires an odd number of voters. So for example in a 4 server FE pool, the SQL backend server will be added as a voting member. When SQL Mirroring is used, only the primary node in the SQL Mirror is assigned to be voter. This means that should the SQL Mirror failover to the secondary node, there will already be 1 less vote in the whole pool. If subsequently two more FE servers were to go down, there will be Pool Quorum Loss and the entire pool will go down, even though technically 50% of the pool is still up and running. Hence its recommended to implement an odd number of FE servers in a Pool when SQL Mirroring is used for backend database HA.
When determining the number of servers running in a pool, Windows Fabric uses a voting process that requires an odd number of voters. So for example in a 4 server FE pool, the SQL backend server will be added as a voting member. When SQL Mirroring is used, only the primary node in the SQL Mirror is assigned to be voter. This means that should the SQL Mirror failover to the secondary node, there will already be 1 less vote in the whole pool. If subsequently two more FE servers were to go down, there will be Pool Quorum Loss and the entire pool will go down, even though technically 50% of the pool is still up and running. Hence its recommended to implement an odd number of FE servers in a Pool when SQL Mirroring is used for backend database HA.
Virtualizing Servers in a FE Pool
While Skype4B servers support virtualization across all workloads, including instant messaging (IM) and presence, conferencing, Enterprise Voice, Monitoring, Archiving, and Persistent Chat, proper placement of servers is vital to ensuring HA works properly in the event of server failures. Since we know that Windows Fabric always creates 3 replicas for every Routing Group and that all users are served by the primary replica of the Routing Group, it will make no sense to place two or more replicas in the same Virtual Host. Should this host go down then immediately the Routing Group will lose quorum and users will experience downtime, even though Pool Quorum may not be lost. Take for example the 5 node FE pool with servers virtualized according to the diagram below:
While Skype4B servers support virtualization across all workloads, including instant messaging (IM) and presence, conferencing, Enterprise Voice, Monitoring, Archiving, and Persistent Chat, proper placement of servers is vital to ensuring HA works properly in the event of server failures. Since we know that Windows Fabric always creates 3 replicas for every Routing Group and that all users are served by the primary replica of the Routing Group, it will make no sense to place two or more replicas in the same Virtual Host. Should this host go down then immediately the Routing Group will lose quorum and users will experience downtime, even though Pool Quorum may not be lost. Take for example the 5 node FE pool with servers virtualized according to the diagram below:
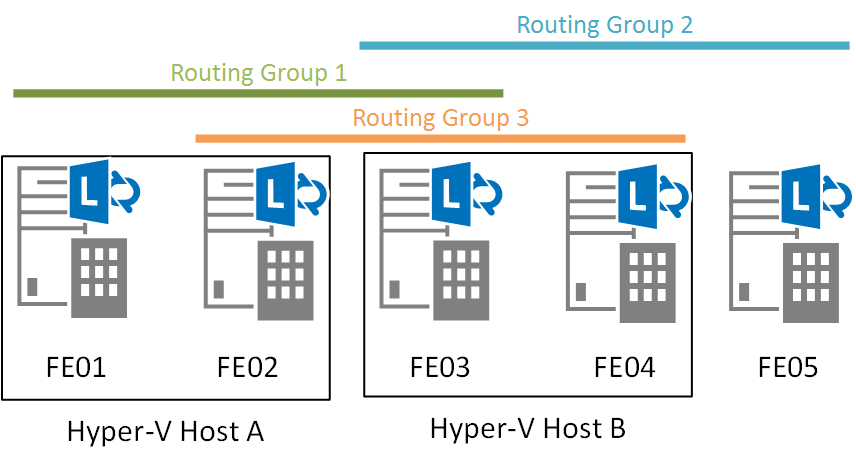
From the above diagram, if we lost Hyper-V Host A due to hardware failure, all users belonging to Routing Group 1 will experience Routing Group Quorum loss and be placed into Limited Functionality mode. While users in Routing Groups 2 and 3 are unaffected since Pool Quorum is still maintained. Therefore, the best practice is place only a single FE node in a Hyper-V host.

 RSS Feed
RSS Feed